上海2016年6月6日電 /美通社/ -- 6月4日,于上海光大會展中心舉行的@Container容器大會上海站,才云科技正式發布了國內首個基于容器集群的分布式深度學習TensorFlow系統Clever。美國谷歌于今年4月底最新發布的TensorFlow 0.8,成功實現了與Kubernetes云平臺的結合。在谷歌內部,TensorFlow已經成功地應用到了谷歌搜索、廣告、地圖、翻譯等眾多產品之中,并突破了語音識別,圖像識別,自然語言處理等多個領域的機器學習瓶頸。TensorFlow代表了美國大規模深度學習的最新進展。才云科技作為國內首家支持分布式TensorFlow的云平臺,引領了國內大數據市場的新發展。

近兩年,Docker、“容器”作為新型軟件交付工具在國內迅速普及,企業都逐漸把容器技術應用在開發環境中,大型容器集群管理方案和實踐也越來越多的被應用于國內企業生產實踐。才云科技主推的谷歌級容器集群管理平臺caicloud.io與基于此平臺向上的各類容器SaaS云服務,已經形成一股高能新引力。這使得才云科技首席科學家鄭澤宇的演講現場全場爆滿,一“站”難求。
深度學習在谷歌中的應用
谷歌內部早在2011年就開始了對大規模并行化深度學習DistBelief系統的搭建。通過該系統,谷歌實現了在語音識別,圖像識別,自然語言處理等多個領域的突破。在語音識別方面,此系統將谷歌語音搜索應用的錯誤率降低了25%;在圖像識別方面,此系統為谷歌贏得了ImageNet 的圖像識別競賽并成功的超越了人類表現;在自然語言處理方面,谷歌翻譯通過此系統進一步提升了翻譯結果。基于DistBelief系統,谷歌于2015年底開源了一套更加靈活,效率更高的深度學習系統 -- TensorFlow。AlphaGo的開發團隊DeepMind也于上個月宣布完全轉移到了TensorFlow這套系統。
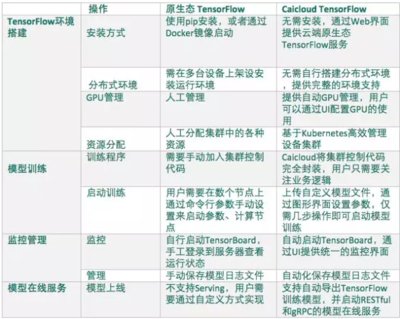
TensorFlow ≠ Hadoop、Spark
因底層計算模型迥異,Hadoop、Spark和TensorFlow有完全不同的擅長和特點。Hadoop和Spark的底層計算框架均基于Map-Reduce,TensorFlow底層則基于矩陣運算。Hadoop和Spark適用于數據的清理、轉化和統計,TensorFlow則更專注于數值計算。比如TensorFlow不容易實現統計單詞出現個數的功能,但可以在短短幾行代碼中實現深度學習算法。
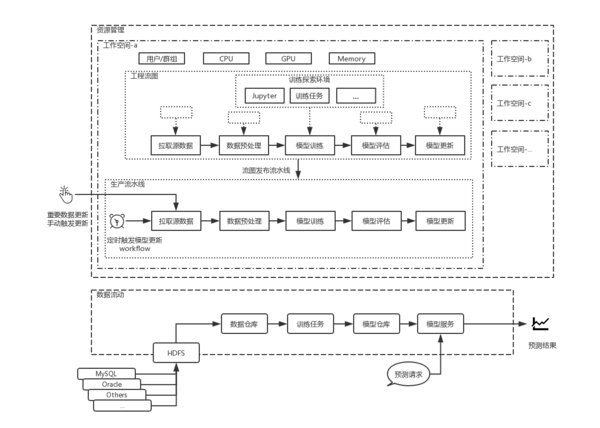
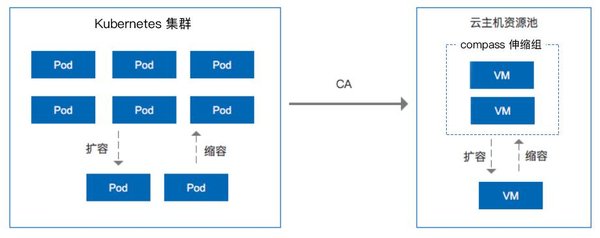
才云科技在國內首推支持分布式TensorFlow系統
為了適應海量數據的需求,才云在6月4日推出Clever 機器學習系統成為國內首家支持分布式TensorFlow系統。基于此系統,才云一方面將進一步提供更加方便的機器學習算法實驗框架,為科研人員提供更好的支持;另一方面也將著力打造深度學習應用SaaS平臺,使得更多的人能夠享受到機器學習帶來的技術革新。